爬虫简单教程
0x00 预备知识
1 | # html |
0x01 基础Python库
1 | # urllib |
0x02 urllib库-学习
urllib.request get方法1
2response = urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode("utf-8"))urllib.request post方法1
2
3
4import urllib.parse
data = bytes(urllib.parse.urlencode({"hello" : "world"}), encoding="utf-8")
response_post = urllib.request.urlopen("http://httpbin.org/post",data = data)
print(response_post.read().decode("utf-8"))urllib.request超时1
2
3
4
5try: #超时处理
response = urllib.request.urlopen("http://www.baidu.com", timeout=1) #时间超过1分钟超时报错
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
print("time out!")当前大多数网站均有反爬机制,比如通过User-Agent简单判断请求来源,因此简单使用以上方法均不适用(请求头直接告诉了网站自己是爬虫),下面也会用一个例子证明
urllib.request.Request1
2
3urllib.request.Request(url,data,head,method)
# url 必有参数 其他可选
# warning: 函数默认method=get方法 post需添method=post下面比较一下使用含有User-Agent的header后的差异:
1
2
3
4
5
6
7
8
9
10
11
12
13#爬取豆瓣TOP250
#仅使用urllib.request get
response = urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode("utf-8"))
#添加header后
url = "https://movie.douban.com/top250"
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36"
}
req = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
0x03 bs4.BeautifulSoup库-学习
官方文档
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 直接复制下面这段也行
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""常用字段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43# 初始化BeautifulSoup对象
soup = BeautifulSoup(html_doc, "html.parser")
# 标准缩进结构输出
print(soup.prettify())
----------------------------------
# BeautifulSoup对象成员是tag: 例如 title、head
soup.title
# <title>The Dormouse's story</title>
soup.title.name
# u'title'
# 获取标签内容
soup.title.string
# u'The Dormouse's story'
# 获取子节点 的 父节点(其他相关成员按需查找文档
soup.title.parent.name
# u'head'
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class']
# u'title'
# 与findall区别,查找第一个<..>标签
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
# 按 属性 查找 第一个
soup.find(id="link3")
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
# 获取全部文字内容
print(soup.get_text())
# 具体其他的需要时翻阅文档
0x04 re库-学习
正则表达式操作符
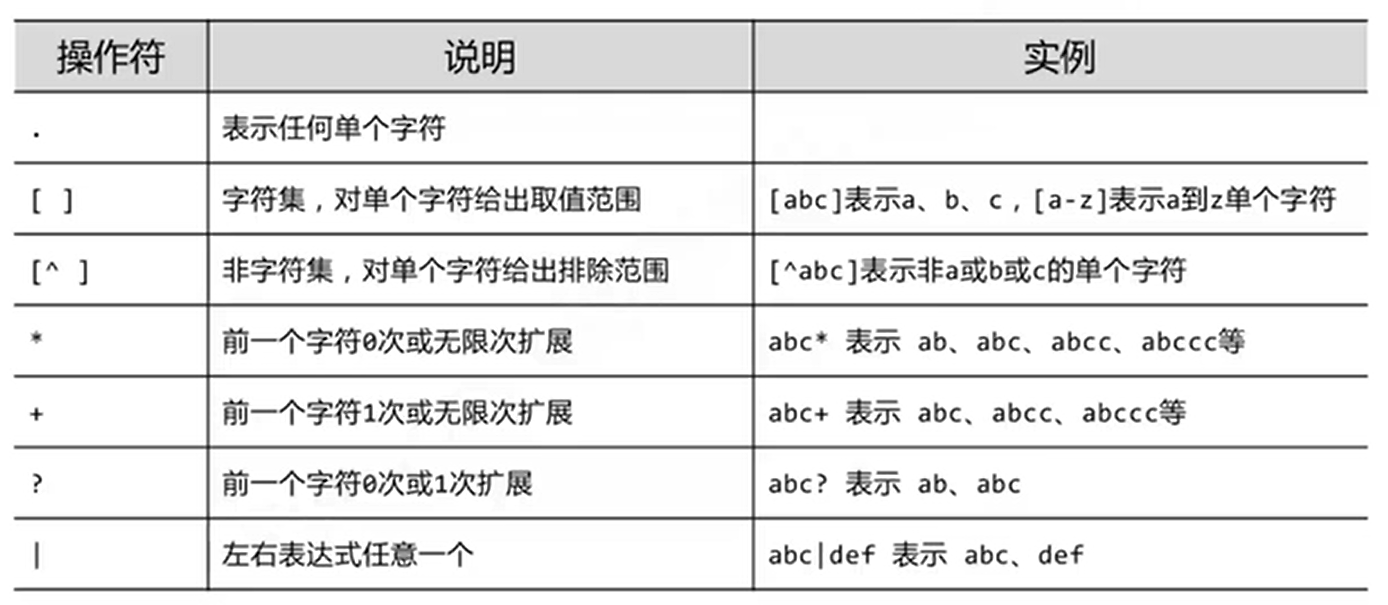
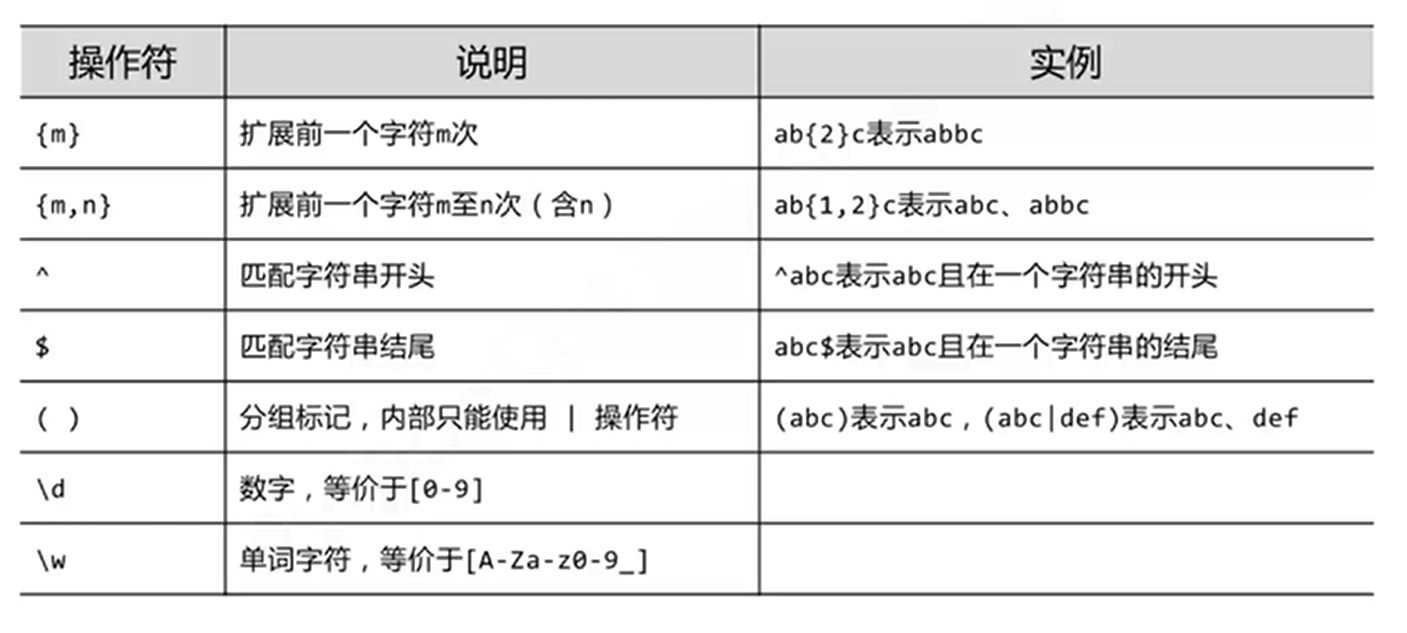
re库函数

1
2
3
4warning: 使用相对较多(排序有先后)
# re.findall
# re.match
# re.sub正则匹配模式
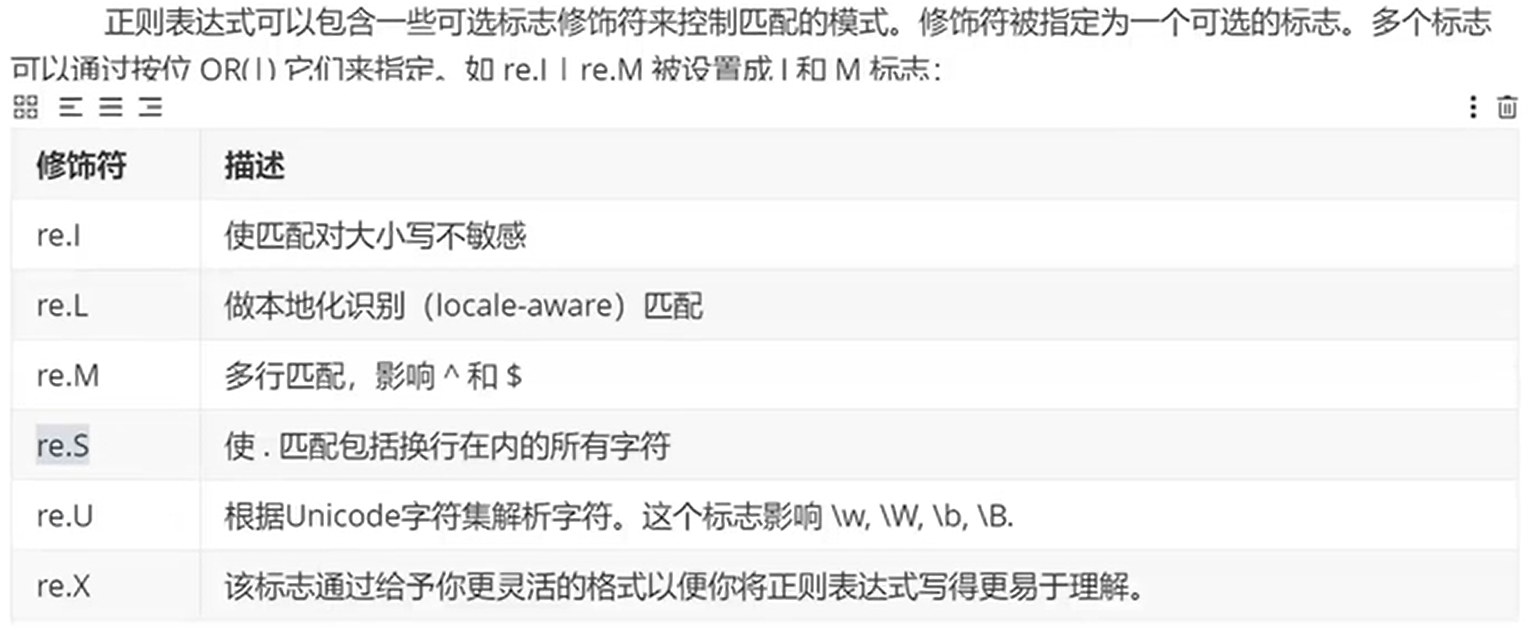
1
2
3warning: 使用相对较多
# re.I
# re.S够用参考模板
0x05 爬虫流程
准备工作
- 确定想要爬取的内容,找到相应的网站
F12,阅读html文档和网络流量,观察得到所需的url和数据位置
获取数据
通过
urllib库获取html文档解析数据
对
html文档进行过滤,通过bs4.BeautifulSoup或者re正则保存数据
将数据进行储存(按需)
0x06 实例
1 | # encoding = utf-8 |